info
-
Attention U-Net 파이토치 구현입니다. 논문을 보고 작성하는데 Gating Signal $g$ 에서 막혀서 시간이 좀 걸렸네요.
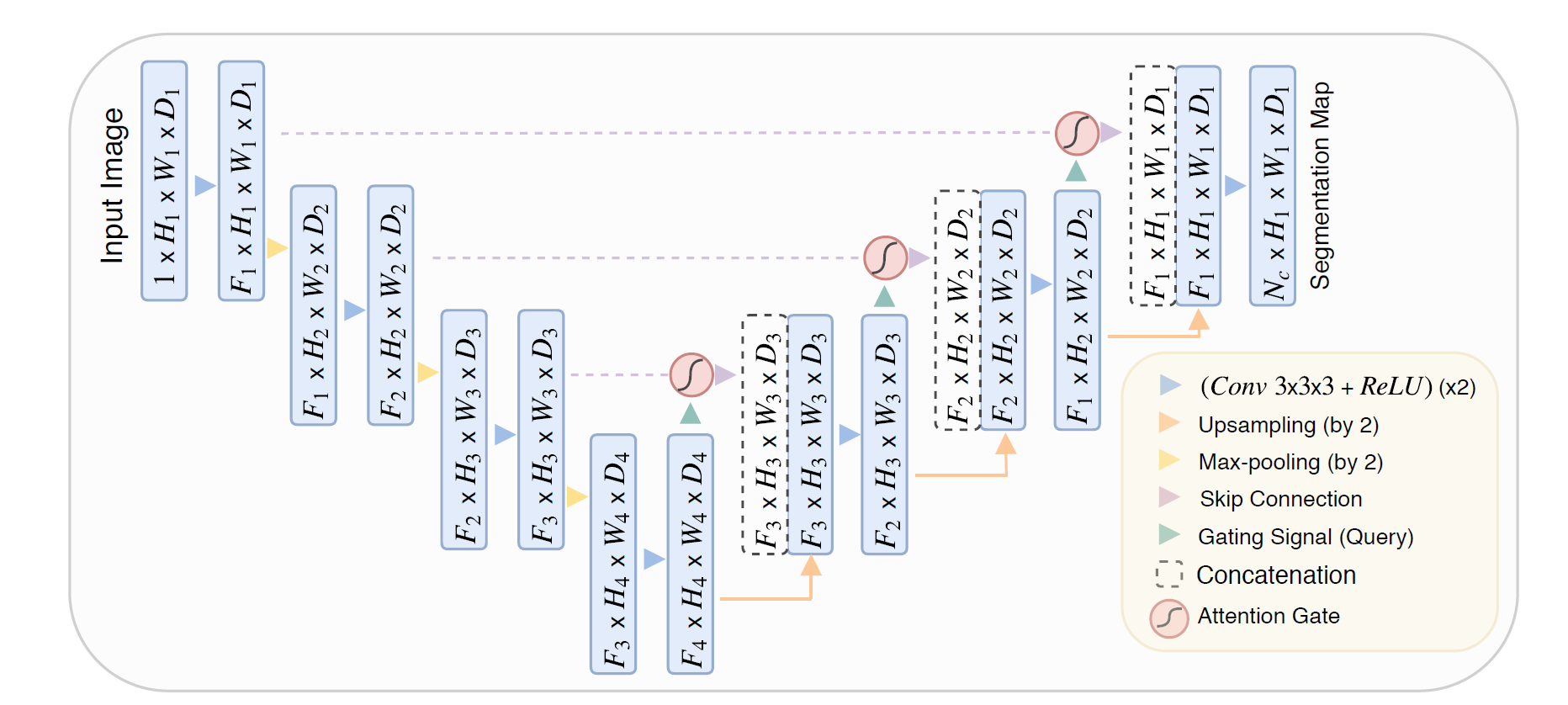
Attention U-Net Encoder, Decoder, 그리고 AttentionGate (softmax, addtive attention)을 구현했습니다.
*Deep supervision은 본문 연구에서 encoder output을 포함하여 stage_outputs들을 모두 segementation map size로 upsampling을 수행 한 후 channel-wise concat을 하여 적용을 했는데 구현 하지 않았습니다.
가졌던 의문이 gating signal $g$를 얻는데 사용되는 Tensor는 $ F_{l+1} \times H_{l+1} \times W_{l+1} \times D_{l+1}$ 의 사이즈를 가지고 있고, Attention gate에 input으로 입력되는 각 encoder의 stage output의 size는 $ F_{l} \times H_{l} \times W_{l} \times D_{l}$ 이여서 volume 3d 영상의 크기가 달라 ( $2*F_l == F_{l+1}$) 바로 연산을 수행할 수 없는..데.. 본문에 별 다른 언급 없이 기술되어 있었네요.
찾아보니, 더 큰 사이즈의 3d 영상을 연산 전에 2x2x2 kernel with 2 strides 로 크기를 맞추어서 수행을 했네요. 그 외에는 다른 2d Attention과 동일합니다.
Attention U-Net 장점 요약
- 향상된 정확도: Attention U-Net의 어텐션 메커니즘을 통해 네트워크는 이미지에서 가장 관련성이 높은 feature에 집중할 수 있으므로 Segmentation 정확도가 향상됩니다.
- False positive/negative 감소: Attention U-Net은 이미지의 가장 중요한(유용한 정보가 포함된) 부분에 초점을 맞춤으로써 Segmentatino 출력에서 False positive와 False Negative의 수를 줄일 수 있습니다.
- 이미지 품질의 변화에 영향을 적게 받음: Attention U-Net은 이미지의 노이즈 또는 아티팩트(촬영장비)에 종속적인 요인과 같은 이미지 품질의 변화에 강인한 것으로 나타났습니다.
- Segmentatino 결과의 더 나은 시각화: Attention U-Net의 어텐션 메커니즘은 Segmentatino 중에 네트워크가 이미지의 어떤 부분에 집중하고 있는지 더 잘 이해할 수 있도록 시각화가 가능한 Attention 맵을 생성할 수 있습니다.
- 다른 작업으로의 이전 가능성: Attention U-Net은 하나의 데이터 세트에서 교육을 받고 최소한의 수정으로 다른 데이터 세트에 적용할 수 있으므로 의료 이미지 분할 작업을 위해 pre-trainined model로 사용할 수 있습니다.
5 advantages of the Attention U-Net
Attention U-Net is a modified version of the U-Net architecture that includes attention mechanisms for medical image segmentation.
- Improved segmentation accuracy: The attention mechanism in the Attention U-Net allows the network to focus on the most relevant features in the image, resulting in improved segmentation accuracy.
- Reduced false positives and false negatives: By focusing on the most informative parts of the image, the Attention U-Net can reduce the number of false positives and false negatives in the segmentation output.
- Robust to variations in image quality: The Attention U-Net has been shown to be robust to variations in image quality, such as noise or artifacts in the image.
- Better visualization of segmentation results: The attention mechanism in the Attention U-Net produces attention maps that can be visualized to better understand which parts of the image the network is focusing on during segmentation.
- Transferability to other tasks: The Attention U-Net can be trained on one dataset and applied to another with minimal modification, making it a highly transferable architecture for medical image segmentation tasks.
Basic operation Module
3D Convolution
- 3x3x3 kernel size convolution
- .. batch-normalisation, ...
- ReLU activation
class ConvLayer(nn.Module):
def __init__(self, in_dim, out_dim, hidden_dim=None) -> None:
super(ConvLayer, self).__init__()
if not hidden_dim:
hidden_dim = out_dim
self.conv = nn.Sequential(
nn.Conv3d(in_dim, hidden_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm3d(hidden_dim),
nn.ReLU(),
nn.Conv3d(hidden_dim, out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm3d(out_dim),
nn.ReLU()
)
def forward(self, x):
return self.conv(x)UpsamplingLayer
class UpsamplingLayer(nn.Module):
def __init__(self, in_dim, out_dim, is_deconv=True) -> None:
super(UpsamplingLayer, self).__init__()
if is_deconv:
self.upsampler = nn.ConvTranspose3d(in_dim, out_dim, kernel_size=2, stride=2, padding=0)
else:
self.upsampler = nn.Upsample(size=out_dim, scale_factor=2, mode='trilinear')
def forward(self, x):
return self.upsampler(x)
Encoder
U-net 흐름과 동일하고 V-net 구현과 pooling을 제외하면 차이가 없습니다.
(Attention U-Net: 2x2x2 max pooling // V-net: pooling을 convolution kernel로 구현)
- Input image is progressively filtered and downsampled by factor of 2 at each scale in the encoding part of the network
- 2x2x2 max pooling
# Encoder
class AttnUNet_Encoder(nn.Module):
def __init__(self) -> None:
super(AttnUNet_Encoder, self).__init__()
self.hidden_dim = 32
self.conv1 = ConvLayer(1, self.hidden_dim)
self.hidden_dim *= 2
self.conv2 = ConvLayer(self.hidden_dim//2, self.hidden_dim)
self.hidden_dim *= 2
self.conv3 = ConvLayer(self.hidden_dim//2, self.hidden_dim)
self.hidden_dim *= 2
self.conv4 = ConvLayer(self.hidden_dim//2, self.hidden_dim)
self.pool = nn.MaxPool3d(2, 2)
def forward(self, x):
h1 = self.conv1(x)
p1 = self.pool(h1)
h2 = self.conv2(p1)
p2 = self.pool(h2)
h3 = self.conv3(p2)
p3 = self.pool(h3)
h4 = self.conv4(p3)
stage_outputs = [h1, h2, h3]
return h4, stage_outputs
Attention Gate
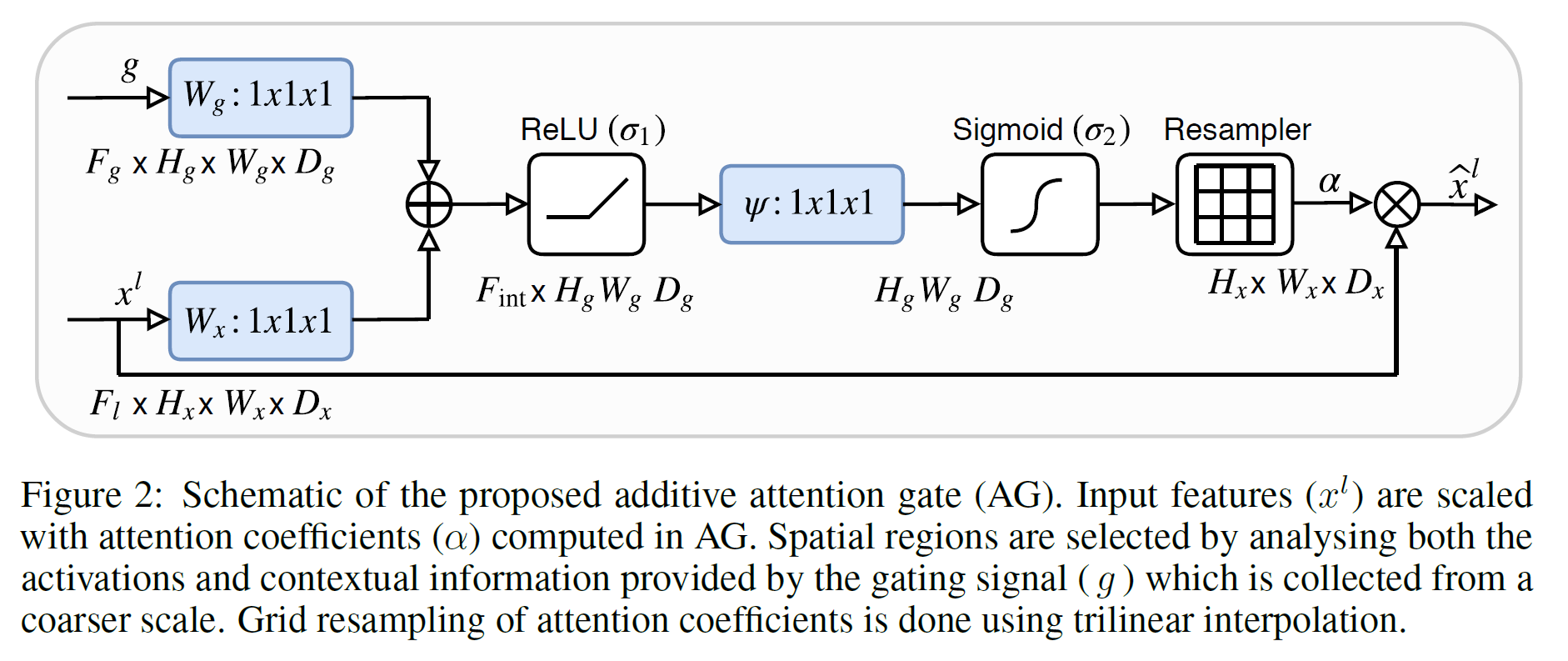
class AttentionGate(nn.Module):
def __init__(self, in_dim, coarser_dim, hidden_dim) -> None:
super(AttentionGate, self).__init__()
self.GridGateSignal_generator = nn.Sequential(
nn.Conv3d(coarser_dim, coarser_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm3d(hidden_dim),
nn.ReLU()
)
# input feature x // the gating signal from a coarser scale
# gating dim == in_dim*2
self.w_x = nn.Conv3d(in_dim, hidden_dim, kernel_size=(2,2,2), stride=(2,2,2), padding=0, bias=False)
self.w_g = nn.Conv3d(coarser_dim, hidden_dim, kernel_size=1, stride=1, padding=0, bias=True)
self.psi = nn.Conv3d(hidden_dim, 1, kernel_size=1, stride=1, padding=0)
def forward(self, inputs, coarser):
query = self.GridGateSignal_generator(coarser)
proj_x = self.w_x(inputs)
proj_g = self.w_g(query)
addtive = F.relu(proj_x + proj_g)
attn_coef = self.psi(addtive)
attn_coef = F.upsample(attn_coef, inputs.size()[2:], mode='trilinear')
return attn_coef
Decoder
# Decoder
class AttnUNet_Decoder(nn.Module):
def __init__(self) -> None:
super(AttnUNet_Decoder, self).__init__()
self.hidden_dim = 32
self.out_dim = 2
self.attn1 = AttentionGate(self.hidden_dim, self.hidden_dim*2, self.hidden_dim)
self.up1 = UpsamplingLayer(self.hidden_dim*2, self.hidden_dim)
self.conv1 = ConvLayer(self.hidden_dim*2, self.out_dim, self.hidden_dim)
self.hidden_dim *= 2 # 32
self.attn2 = AttentionGate(self.hidden_dim, self.hidden_dim*2, self.hidden_dim)
self.up2 = UpsamplingLayer(self.hidden_dim*2, self.hidden_dim)
self.conv2 = ConvLayer(self.hidden_dim*2, self.hidden_dim, self.hidden_dim)
self.hidden_dim *= 2 # 64
self.attn3 = AttentionGate(self.hidden_dim, self.hidden_dim*2, self.hidden_dim)
self.up3 = UpsamplingLayer(self.hidden_dim*2, self.hidden_dim)
self.conv3 = ConvLayer(self.hidden_dim*2, self.hidden_dim, self.hidden_dim)
def forward(self, enc_out, stage_outputs):
attn_g3 = self.attn3(stage_outputs[-1], enc_out) * stage_outputs[-1]
h3 = self.up3(enc_out)
h3 = torch.concat([attn_g3, h3], dim=1)
h3 = self.conv3(h3)
attn_g2 = self.attn2(stage_outputs[-2], h3) * stage_outputs[-2]
h2 = self.up2(h3)
h2 = torch.concat([attn_g2, h2], dim=1)
h2 = self.conv2(h2)
attn_g1 = self.attn1(stage_outputs[-3], h2) * stage_outputs[-3]
h1 = self.up1(h2)
h1 = torch.concat([attn_g1, h1], dim=1)
h1 = self.conv1(h1)
return h1
Attention U-Net
class Attn_UNet(nn.modules):
def __init__(self) -> None:
super(Attn_UNet, self).__init__()
self.encoder = AttnUNet_Encoder()
self.decoder = AttnUNet_Decoder()
def forward(self, inputs):
enc_out, stage_outputs = self.encoder(inputs)
out = self.decoder(enc_out, stage_outputs)
return out
