본 게시글에 작성되는 내용은 PyTorch Lightning 공식 사이트에 있는 Tutorial과 API Docs를 참고하여 작성하였습니다. 그 외에 블로그에 작성된 몇 개의 예제들을 더 참고했는데, PyTorch-Lightning이 추구하는 '효과적인 추상화'를 위해서는 이러한 방향으로 사용하면 더 좋을 수 있겠다 싶어서 글로 공부했던 내용을 글로 정리했습니다.
PyTorch Lightning 소개

PyTorch Llightning은 PyTroch에 대한 High-level (abstract) 인터페이스를 제공하는 오픈소스 라이브러리 입니다. PyTorch 하나만으로도 숙달되면 부족함은 전혀 없지만, 모델이 커질 수록 그리고 다양하고 고도화된 기술들을 적용하면서 실험을 할 경우 코드가 너무 복잡해집니다. 이러한 관점에서 딥러닝, 특히 PyTorch 프레임워크를 사용하여 문제를 푸는 사람들에게 연구 외의 부담을 해소하고자 출현하게 된 프레임워크입니다. 코드를 추상화를 통해 더 간결하게 변경할 수 있으며, 직관적인 코드 스타일을 추구합니다. 이를 통해 연구자들은 실제로 다루어야하는 문제들에 대해서 더 집중을 할 수 있게 되어 bolierPalte 코드 (예: for loop로 구성된 클리셰적인 코드들) 에서 일부 수정하는데 드는 소요와 디버깅 부담을 획기적으로 쳐 낼 수 있습니다.
PL 장점
실제로 공식 문서를 읽거나 블로그 글을 읽으면서 마주하게된 장점은 다음과 같습니다.
- PyTorch로 작성된 코드를 매우 간결하게 작성할 수 있게 해주며 그 덕에 모듈화가 쉬워진다. (기존의
forloop statement로 즐비해있던 PyTorch 기반 학습코드 더미들을 처리할 수 있습니다) - PyTorch code 기반을 작성되었기 때문에 새로운 문법은 없으며 본인이 필요한 기능은 @override를 통해 모두 재정의 할 수 있습니다. 추가로 PyTorch Lightning에서 제공하는 기능을 통해 추가적으로 필요에 따라서 자유롭게 확장해 나갈 수 있습니다.
- CPU, (multi-)GPU/TPU, 16-bit precision 등 다양한 학습 방법에도 유연하게 적용이 가능합니다.
- 조밀하게 구성되어 있는 공식 Docs와 항상 함께 준비된 많은 예제 코드가 있습니다.
특히 요즘은 튜토리얼 혹은 베이스라인이 *.ipynb로 구성되는 예제가 많습니다. 그리고 보통 딥러닝 파이프라인은 데이터-모델-학습함수-학습-... 등으로 순서를 갖는 코드를 많이 사용을 하게 되는데, 구성된 코드에서 학습을 하다가 에러가 난 경우 혹은 실험을 다른 설정으로 하고 싶어 코드를 변경해야하는 경우에는 본인의 기억에 의지하여 마우스 스크롤을 열심히 하며 코드의 위치를 찾아가야 합니다.
단적인 예로 학습할 때의 모델의 출력을 가지고 다른일을 하고 싶다면 (기억에 의존하여) for batch_idx, (x,y) in enumrate(dataLoader): ... 로 구성된 코드에 찾아가서 이를 수정을 해야합니다. 이는 한 종류의 작업만 수행한다면 큰 문제가 되지 않지만 기간에 따라 새로운 문제를 풀어야하는 경우에는 데이터-모델-학습함수-학습-... 의 구조를 적절하게 기워 맞춘다음에 일부씩 수정하는 동작을 반복해야하는 번거로움이 항상 존재합니다.
위와 같은 경험이 있거나, Challenge에 참가할 때마다, 혹은 연구 중인 곳에서 새로운 주제를 시작할 때에 마다 의미 없는 코드 수정으로 인해 추상화에 대한 필요성을 느껴보셨다면 PyTorch-Lightning을 한 번 둘러보시면 좋을 것 같습니다. 실제로 Computer Vision AI를 다루시는 분들 중에서는 Segmentation, Classification, Object-detection, Generation 등 전환이 매우 쉽고 코드가 간결해져서 PyTorch-Lightning에서 헤어나오지 못하고 계시다는 간증(?)도 있습니다.
예시) MNIST 데이터 셋의 학습을 위한 코드 비교
먼저 Pytorch로 작성을 하고, for loop를 이용한 예제입니다. 예제 코드는 wikidocs.net에서 가져왔습니다.
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# 예측(prediction)과 손실(loss) 계산
pred = model(X)
loss = loss_fn(pred, y)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
print("Done!")간단한 image data classification을 수행하는 코드입니다. 사용하는 학습 전략이 단순하고 복잡하지 않은 문제를 풀기 때문에 코드가 짧은 편이나, 학습을 수행하는 코드의 길이는 이보다 짧아지기 어렵습니다.
다음은 Lightning을 사용한 예시입니다.
model = LitModel()
trainer = Trainer(max_epochs=epochs, gpus=0)
trainer.fit(model, train_dataloader, val_dataloader)
trainer.test(test_dataloaders=test_dataloader)학습에 수행되는 코드가 매우 간결해졌음을 알 수 있습니다.
c.f. 설치와 사용
대부분 pip 명령어를 통한 설치 방법을 다루고 있는데 pip와 conda를 통해서도 설치를 수행할 수 있습니다.
# 공식 홈페이지 안내
python -m pip install lightning
# 공식 홈페이지 conda install
conda install pytorch-lightning -c conda-forge
# 공식 GitHub 안내; Simple installation from PyPI
# Optimized for model development
pip install pytorch-lightning
또, PyTorch Llightning은 관례적으로 pl로 축약해서 사용을 합니다.
import pytorch_lightning as pl
PyTorch-Lightning Core API; 핵심 요소 2가지

PyTorch Lightning은 크게 2가지를 중심으로 코드의 추상화와 간결화를 만들어냅니다. 하나는 딥러닝 모델 + 학습시 동작 설정 + 데이터를 다룰 수 있는 LightningModule입니다. 다른 하나는 학습시 전략, 환경설정 등을 제어할 수 있는 Trainer입니다.
좀 더 자세하게는 PyTorch로 구성했었던 loop 위주의 코드를 6개의 영역으로 Restructing, Simplifing 할 수 있습니다.
- Computations; __init__
- Train loop (
for epoch in range(epochs): .../for idx, (x, y) in enumerate(train_loader): ...) - Validation loop (
for idx, (x,y) in enumerate(val_lodaer): ...) - Test loop (
for idx, (x,y) in enumerate(test_lodaer): ...) - prediction loop ( 동일 )
- Optimizers and LR Schedulers
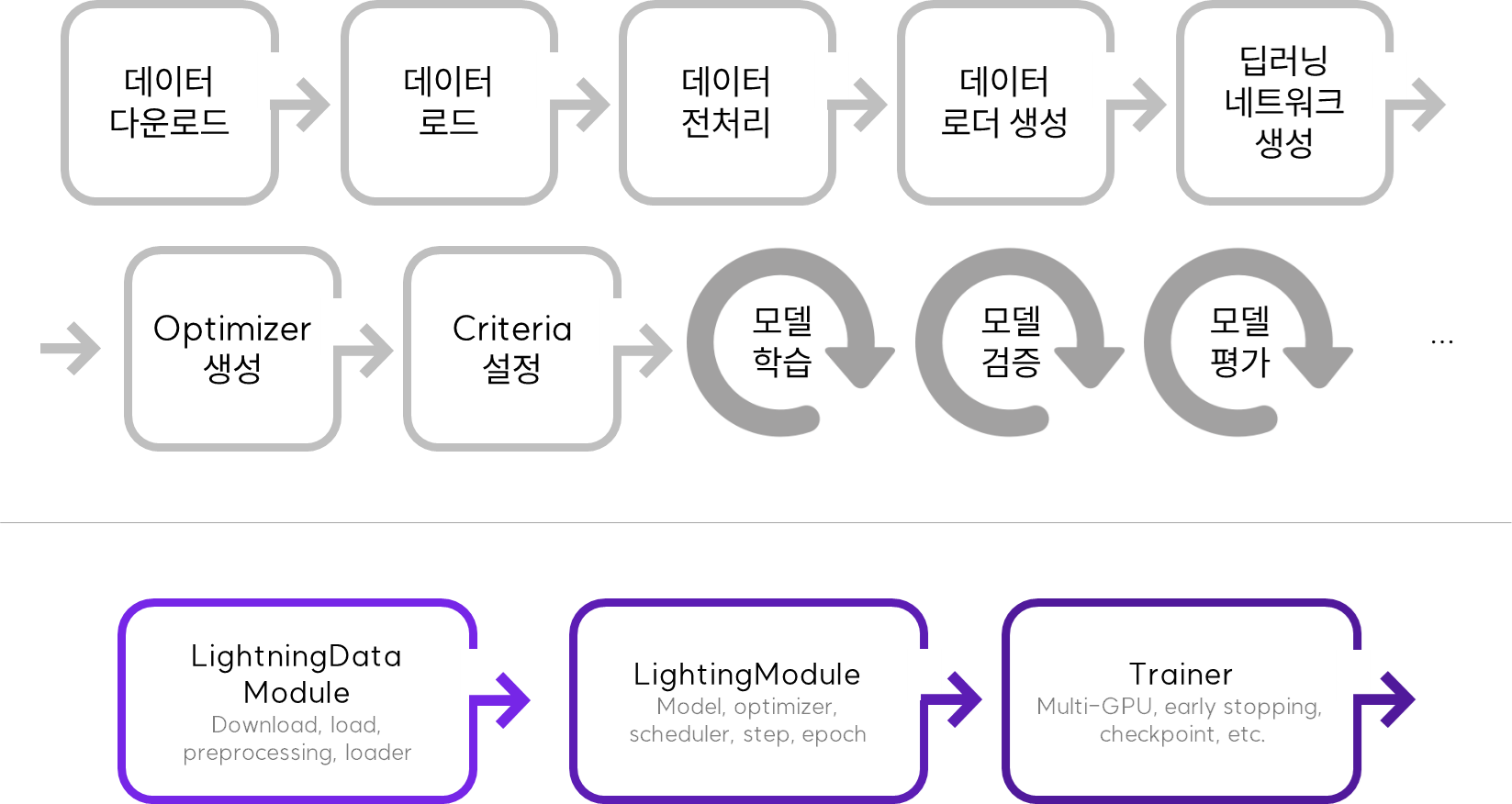
여기에 추가로 저는 LightningDataModule을 사용해서 데이터를 다루는 것을 따로 떼어놓아서 관리를 하는 방법이 더 좋아보입니다. LighningModule을 사용하는 클래스에서는 딥러닝 모델과 매 step(배치)마다 혹은 매 epoch 마다의 동작만 관리하도록하여 데이터는 따로 모듈화를 한다면 PyTorch-Lightning이 궁극적으로 원하는 방향대로 갈 수 있지 않을까 하는 생각이 있습니다.
(*LighningDataModule에서 사용하는 method는 LightingModule에 사용해도 동일합니다. 저는 모듈화를 고려해서 사용하는 것일 뿐이지 차이는 없습니다)
LighningModule 클래스
공식 홈페이지에서는 총 7개의 함수가 the core methods 라고 합니다: __init__(), forward(), training_step(), validation_step(), test_step(), predict_step(), configure_optimizers().
그러나 실제로 test_step(), predict_step()은 큰 차이가 없고, 필요시에는 forward() 함수를 통해서 출력을 얻은 후 클래스 밖에서 처리를 수행하는 편이 낫다고 생각이 되었습니다. 그래서 사용을 위해서는 아래의 3가지 요소들을 보려고 합니다. (*model template이 많거나, task의 수행 후의 결과를 저장하는 방식이 정형화된 경우에는 필요할 수 있음)
- 모델 기본 구조 - Model construction & Forward()
- 모델 학습 함수 (반복) - loop methods
- training, validation, test
- _step, step_end, _epoch_end
- Optimizers & LR Schedulers configuration
모델 기본 구조 - Model construction & Forward()
model constructor: 기존 PyTorch 기반 네트워크를 정의할 때 혹은 class를 사용하는 것과 동일하게 구성할 수 있습니다. 사용할 딥러닝 모델을 생성하거나 혹은 딥러닝 모델의 레이어를 나열하여 저장할 수 있습니다.
class LightningRunner(LightningModule):
def __init__(self, CNN, loss, args):
super().__init__()
self.model = CNN(args)
self.loss = torch.nn.MSELoss()
self.args = args
################## OR ###################
class LightningRunner(LightningModule):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(28 * 28, 1000)
self.linear2 = nn.Linear(1000, 10)
self.act = nn.SiLU()
forward(): torch.nn.Module을 상속받아서 구현한 모델이 가지는 것과 동일하게 forward propagation을 수행하는 코드를 동일하게 작성해주시면 됩니다.
def forward(self, x):
return self.model(x) # self.model = CNN
################### OR #####################
def forward(self, x):
x = x.view(x.size(0), -1)
h = self.linear1(x)
h = self.act(h)
out = self.linear2(h)
return out필요에 따라서 custom loss function을 inner method로 선언을 해서 사용하는 것도 관리 운용면에서 좋은 선택처럼 느껴집니다.
모델 학습 함수 (반복) - loop methods
PyTorch-Lightning이 번거롭고 복잡하게 작성하고 운영하던 for loop 부분을 추상화한 부분입니다.
일반적으로 루프 패턴(반복 호출되는 함수 - training, valdiation 등)은 4가지의 동작과 3가지의 타이밍을 가지고 있습니다.
4가지의 동작: {training, validation, test, predict}
3가지의 패턴: {_step (매 스탭, 배치마다), _step_end (매 스탭이 끝난 후, 보통 multi-GPU의 결과 취합), _epoch_end (1 epoch가 끝 난 후}
동작 이름에, 반복 패턴을 붙여서 메소드를 활성화(@override)합니다. 일반적으로는 training_step(), validation_step(), validation_epoch_end() 3가지 메소드에 추가적으로 training_step_end()를 사용합니다.
class LightningRunner(LightningModule):
def __init__(self, ...):
...
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
pred = ...
return {"loss": loss, "pred": pred}
def training_step_end(self, batch_parts):
# predictions from each GPU
predictions = batch_parts["pred"]
# losses from each GPU
losses = batch_parts["loss"]
gpu_0_prediction = predictions[0]
gpu_1_prediction = predictions[1]
# do something with both outputs
return (losses[0] + losses[1]) / 2
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
self.log("val_loss", loss)
pred = ...
return pred
def validation_epoch_end(self, validation_step_outputs):
# outputs is an array with what you returned in validation_step for each batch
all_preds = torch.stack(validation_step_outputs)
...- _step(): training loop에서 수행할 동작을 정의하는 것 - for statement로 정의했던 동작을 method override를 통해 활성화.
- _step_end(): 한 step(single batch)의 수행이 끝난 후에 수행되는 메소드. 여러개의 GPU 장치에 올린 배치들을 하나로 받아서 처리하는 경우에 사용할 수도 있다.
- _epoch_end(): _step() 함수의 outputs을 가지고 무언가를 하려고 하는 경우에 사용하는 메소드. input으로 들어오게 되는 인자는 array의 형태이다.
위에서 사용된 self.log는 PL이 제공하는 logger로, 해당 방법을 따르지 않고 validation_step 마다 동작을 정의해서 사용할 수도 있습니다.
Optimizers & LR Schedulers configuration
모델을 학습시킬 때, 어떤 optimizer와 LR Scheduler를 사용할 것인지를 configure_optimizers() 메소드를 통해 정의할 수 있습니다. 해당 메소드에서 Scheduler 없이 optimizer만 사용하는 것도 가능하고, 각각 여러개를 사용하는 것도 가능합니다.
공식 문서에서는 6개의 리턴옵션이 존재한다고 합니다: 1) optimizer 한개, 2) optimizer 여러개 - i.e. GAN, 3) 2개 리스트 - optmizer들이 있는 것, scheduler가 있는 것, 4) dict 자료구조 - 'optimizer' 등 key로 optimizer와 scheduler를 매핑한 사전, 5) dict가 담긴 튜플, 6) None.
아래는 공식 홈페이지에서 제공하는 케이스별 메소드 리턴의 예제를 모아놓은 것입니다. 이를 통해 해당 메소드가 어떻게 사용해야하는지 참고하실 수 있을 것 같습니다. (여담이지만 optimizer 하나만 사용하는 예제 코드를 작성해놓은 블로그들이 대부분이었는데 별도의 설명없이 return optimizer 혹은 return [optimizer] 로 코드가 작성이 되어있었습니다. 혼선을 방지하고 싶어서 해당 언급과 예시를 가져왔습니다. 결국 둘 다 차이가 없는 코드입니다.)
from torch.optim import Adam, SGD, ...
# most cases. no learning rate scheduler
def configure_optimizers(self):
return Adam(self.parameters(), lr=1e-3)
# multiple optimizer case (e.g.: GAN)
def configure_optimizers(self):
gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
dis_opt = Adam(self.model_dis.parameters(), lr=0.02)
return gen_opt, dis_opt
# example with learning rate schedulers
def configure_optimizers(self):
gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
dis_opt = Adam(self.model_dis.parameters(), lr=0.02)
dis_sch = CosineAnnealing(dis_opt, T_max=10)
return [gen_opt, dis_opt], [dis_sch]
# example with step-based learning rate schedulers
# each optimizer has its own scheduler
def configure_optimizers(self):
gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
dis_opt = Adam(self.model_dis.parameters(), lr=0.02)
gen_sch = {
'scheduler': ExponentialLR(gen_opt, 0.99),
'interval': 'step' # called after each training step
}
dis_sch = CosineAnnealing(dis_opt, T_max=10) # called every epoch
return [gen_opt, dis_opt], [gen_sch, dis_sch]
# example with optimizer frequencies
# see training procedure in `Improved Training of Wasserstein GANs`, Algorithm 1
# https://arxiv.org/abs/1704.00028
def configure_optimizers(self):
gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
dis_opt = Adam(self.model_dis.parameters(), lr=0.02)
n_critic = 5
return (
{'optimizer': dis_opt, 'frequency': n_critic},
{'optimizer': gen_opt, 'frequency': 1}
)
# In the case of two optimizers, only one using the ReduceLROnPlateau scheduler
def configure_optimizers(self):
optimizer1 = Adam(...)
optimizer2 = SGD(...)
scheduler1 = ReduceLROnPlateau(optimizer1, ...)
scheduler2 = LambdaLR(optimizer2, ...)
return (
{
"optimizer": optimizer1,
"lr_scheduler": {
"scheduler": scheduler1,
"monitor": "metric_to_track",
},
},
{"optimizer": optimizer2, "lr_scheduler": scheduler2},
)
추가로, LR scheduler는 LR scheduler instance만 전달하는 것 말고도 lr_scheduler_config의 형태로도 사용이 가능합니다. 아래는 예제로 scheduler만 전달되었을 때의 기본 설정입니다.
lr_scheduler_config = {
# REQUIRED: The scheduler instance
"scheduler": lr_scheduler,
# The unit of the scheduler's step size, could also be 'step'.
# 'epoch' updates the scheduler on epoch end whereas 'step'
# updates it after a optimizer update.
"interval": "epoch",
# How many epochs/steps should pass between calls to
# `scheduler.step()`. 1 corresponds to updating the learning
# rate after every epoch/step.
"frequency": 1,
# Metric to to monitor for schedulers like `ReduceLROnPlateau`
"monitor": "val_loss",
# If set to `True`, will enforce that the value specified 'monitor'
# is available when the scheduler is updated, thus stopping
# training if not found. If set to `False`, it will only produce a warning
"strict": True,
# If using the `LearningRateMonitor` callback to monitor the
# learning rate progress, this keyword can be used to specify
# a custom logged name
"name": None,
}
코드로 재정리
LightningModule을 사용하여 class를 정의할 때 포함되어야할 핵심 3파트를 보았습니다. 네트워크를 포함한 모델의 기본 구조를 형성하는 model construction과 forward(), 모델의 학습 때의 반복 동작을 정의하는 loop method defining, 그리고 학습 때에 어떻게 최적화 될 것인지를 정의하는 Optimizers & LR Schedulers configuration. 아래는 가장 간단한 LightningModule을 만드는 코드입니다.
class LightningRunner(LightningModule):
def __init__(self, CNN, loss, args):
super().__init__()
self.model = CNN(args)
self.loss = torch.nn.MSELoss()
self.args = args
def configure_optimizers(self):
return Adam(self.parameters(), lr=1e-3)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
pred = ...
return {"loss": loss, "pred": pred}
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
self.log("val_loss", loss)
pred = ...
return pred
def validation_epoch_end(self, validation_step_outputs):
# outputs is an array with what you returned in validation_step for each batch
all_preds = torch.stack(validation_step_outputs)
...
LightningModule 통해 모델의 선언, 학습 동작, back prop 때 사용할 optimizer 까지 학습에 필요한 요소들을 모두 묶었습니다.
LightningDataModule 클래스
coreAPI로 소개되고 있지는 않지만, 여러 연구와 competition을 직간적접으로 참여하면서 필요하다고 느꼈던 module입니다.
마찬가지로, LightningDataModule 클래스도 잘짜여진 예제와 문서와 함께 공식홈페이지에 존재합니다.

PyTorch를 사용해서 데이터를 다룰 때는 1) 데이터 다운로드, 2) 데이터 적재 및 전처리 (transform, split.. etc), 3) dataloader로 포장하는 단계들을 거쳐왔었는데, 이 또한 Lightning에서 추상화를 수행해 놓았습니다. 왼편의 PyTorch 기반의 코드들이 즐비해 있고 train, test, validation, .. 등을 위해서 코드가 지속적으로 반복되고 추후에 관리하기 번거로움이 있는데, DataModule을 통해서 이를 모듈화 한 뒤에 실제 코드 실행때에는 간단한 호출로만 학습을 수행할 수 있음을 데이터 클래스 데모 비디오에서 보여주고 있습니다.
DataModule의 parepare_data(), setup(), train_dataloader(), val_dataloader(), test_dataloader(), predict_dataloader() 함수들을 통해서 training, validation, test, predict에 맞는 데이터를 보다 간결하게 제공할 수 있습니다.
위의 함수들은 앞서 말했듯이 LightningModule 클래스에도 메소드 오버라이드를 통해 활성화할 수 있습니다. 그리고 동일합니다. 하지만 모듈화를 고려했을 때, 데이터 패키지 관리가 이후에도 용이했으면 좋겠다 싶어서 DataModule class를 참고하여 작성을 하였습니다. (예시, 이미지 데이터의 transform을 위해서 model-runner class가 아닌 data class에 접근하는게 더 편리하고 직관적이라고 생각)
DataModule 클래스 예제 코드
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str = "./"):
super().__init__()
self.data_dir = data_dir
self.transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
def prepare_data(self):
# download
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage: str):
# Assign train/val datasets for use in dataloaders
if stage == "fit":
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Assign test dataset for use in dataloader(s)
if stage == "test":
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
if stage == "predict":
self.mnist_predict = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=32)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=32)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=32)
def predict_dataloader(self):
return DataLoader(self.mnist_predict, batch_size=32)데이터 소스가 있는 dir path, 학습에 사용될 batch size의 설정, 전처리 혹은 데이터 증강에 사용될 transform을 class attr로 받고, setup에서 호출되는 메소드에 따라서 데이터를 알맞게 준비를 합니다.
본 문서에서는 prepare_data() 함수에서는 self.train = train_data 등의 state를 저장하지 말라고 경고하고 있습니다.
각 train, val, test, predict _dataloader 메소드는 Trainer.fit(), Trainer.validate(), Trainer.test(), Trainer.predict()가 호출되면 사용이 됩니다.
코드가 간결해지거나, 참신한 무언가가 있는 것은 아니지만 데이터를 관리하는 클래스(LightningDataModule)가 모델 클래스(LightningModule)와 함께 학습에 유기적으로 동작한다는 점, 그리고 데이터를 다루는 클래스의 모듈화로 인해 언제든 데이터에 대한 관리-처리 등에 대한 효율이 올라갈 수 있다는 점에서 장점이 있다고 느껴졌습니다.
Trainer 클래스
from pytorch_lightning import Trainer
model = MyLightningModule()
trainer = Trainer()
trainer.fit(model)
######## PyTorch e.g. ############
# put model in train mode
model.train()
torch.set_grad_enabled(True)
losses = []
for batch in train_dataloader:
# calls hooks like this one
on_train_batch_start()
# train step
loss = training_step(batch)
# clear gradients
optimizer.zero_grad()
# backward
loss.backward()
# update parameters
optimizer.step()
losses.append(loss)for loop의 코드를 간결하게 바꾸어 처리해주는 Trainer 클래스입니다. 클래스의 동작을 보면 모델의 training이 sklearn의 fit() 메소드처럼 추상화되어 간결화 되었습니다. 그 밑에 위치시킨 기존의 PyTorch 기반의 동작코드는 개발자가 구성해주어야하는 BoilerTamplet 코드가 항상 따라왔고, for statement를 통해 반복 동작에 대한 제어를 수행해야했습니다. Trainer 클래스를 사용하면 기존에 사용하던 코드들을 작성할 필요가 없어집니다.
또한 training, validation, test, prediction을 수행하기 위해서는 아래의 코드에 작성된 메소드를 호출하면 됩니다.
trainer.fit()
trainer.validate()
trainer.test()
trainer.predict()
Trainer Flags
Trainer instance를 생성할 때, constructor에 flags를 설정하여 학습 전략이나 환경을 지정할 수 있습니다. 다음은 몇 가지 예입니다.
- acceleartor - 'cpu', 'gpu', 'tpu',' ipu',' auto'
- devices - gpu 등 사용할 device idx 전달
- max_epochs - training 때에 최대 epoch 설정
- precision - 16 precision 사용 가능
- accumulate_grad_batches - batch size를 가변할 수 있음
- auto_lr_find - learning rate finder를 실행시켜서 LR를 찾음
- callback; early stopping, checkpoint - early stopping 기술 혹은 best model 추출 등
그 밖에도 사용할 수 있는 옵션이 매우 많습니다 (참고). PyTorch 프레임워크 하나만으로는 사용하려면 많은 공부 혹은 세팅이 필요한 설정들도 Trainer Flag로 전달하여 활용할 수 있는 점은 매우 매력적이라고 생각합니다. 아래는 flag 만으로 multi-gpu 세팅을 할 수 있는 예제 코드입니다.
# multi-device ex
# CPU accelerator
trainer = Trainer(accelerator="cpu")
# Training with GPU Accelerator using 2 GPUs
trainer = Trainer(devices=2, accelerator="gpu")
# Training with TPU Accelerator using 8 tpu cores
trainer = Trainer(devices=8, accelerator="tpu")
# Training with GPU Accelerator using the DistributedDataParallel strategy
trainer = Trainer(devices=4, accelerator="gpu", strategy="ddp")
# Training with CPU Accelerator using 2 processes
trainer = Trainer(devices=2, accelerator="cpu")
# Training with GPU Accelerator using GPUs 1 and 3
trainer = Trainer(devices=[1, 3], accelerator="gpu")
# Training with TPU Accelerator using 8 tpu cores
trainer = Trainer(devices=8, accelerator="tpu")
GPU 세팅 이외에도 callback flags는 다음과 같이 사용할 수 있습니다. 해당 사용은 DACON competition에서 공개 토크에서 공유가 되었습니다.
checkpoint_callback = ModelCheckpoint(
monitor='val_score',
dirpath=config['checkpoint_dir'],
filename=f'{config["model_name"]}'+'-{epoch:02d}-{train_loss:.4f}-{val_score:.4f}',
mode='max'
)
early_stop_callback = EarlyStopping(
monitor="train_loss",
patience=3,
verbose=False,
mode="min"
)
pl_video_model = PLVideoModel(config)
trainer = pl.Trainer(
max_epochs=100,
accelerator='auto',
precision=16,
callbacks=[early_stop_callback, checkpoint_callback]
)
trainer.fit(pl_video_model, train_dataloader, val_dataloader)
글을 마치며
PyTorch Lightning은 문서화가 매우 잘 되어있습니다. Tutorial도 수준 별로 정리가 되어 있어서 Lightning을 처음 사용해보시는 분들부터 실무에 적용할 수 있는 영역까지 존재합니다. 본 글의 설명이 완벽하지 않기 때문에 초심자분들은 Level Up - Basic skills 의 내용을 살펴보시면 더 큰 도움이 될 수 있을 것 같습니다. 물론 저도 Basic skills를 참고해야 해당 라이브러리를 십분 활용할 수 있겠다고 생각듭니다.
의미없이 반복되고 일부 수정되는 코드와 모듈화와 추상화의 갈급함이 있어서 이리저리 기웃거리던 와중에 찾게 된 PyTorch-Lightning입니다. 볼 수록 상당히 Fancy 하다는 느낌이 강하고 PyTorch modeling에 어느정도 익숙해지신 분들이라면 더 큰 효과와 효율을 얻을 수 있을 거라는 생각이 드네요. 2018년도부터 시작한 라이브러리니, 학부생때 매번 online competition에 참여하면서 배우고 PyTorch Lightning의 사용을 체화했다면 깃허브가 좀 더 보기 좋게 되어있지 않았을까하는 생각도 듭니다.
아무튼 매력적이고 배우기 좋은 라이브러리임이 분명하니, 한 번 참고하면 좋을 것 같습니다.
감사합니다.
'개발새발 > 개발 셋업' 카테고리의 다른 글
| PyTorch 모델 특정 종류의 레이어를 바꾸기 (0) | 2023.03.16 |
|---|---|
| 윈도우 포맷 후 환경 설정 및 설치 체크리스트 (0) | 2023.02.24 |
| [Docker, Linux] GPG에러 해결, public key 수동 설치 (apt-get이 에러가 발생하며 동작하지 않을 때) (0) | 2023.01.19 |
| [Docker] 서버 Docker, miniconda 개발 환경 세팅 (1) | 2023.01.18 |
| [Conda] 컴퓨터비전을 위한 토치환경 셋업 (0) | 2023.01.18 |
